1 Abstract¶
We present a mechanism for exposing user files via WebDAV, so that there are ways to get to those files that are not dependent on having a running RSP JupyterLab instance.
We have a requirement for users to be able to read and write their files from their desktop environments. One obvious use-case is so that users can use their favorite editors without requiring that we provide all possible editors in the RSP environment. Many such editors (e.g. VSCode) would require us to forward a graphical connection to a virtualized user desktop (presumably provided by X or VNC), which would open up a new attack surface within the RSP lab, be fairly heavyweight, and would yield a host of associated maintenance issues around providing a mechanism for that network forwarding.
On the other hand, WebDAV seems like a reasonable mechanism to allow file manipulation; it is, after all, a protocol extension to HTTP, and we are by definition already providing HTTP access to RSP resources.
2 Chosen Approach¶
This is not a new idea; user file access to resources in the RSP has been something we’ve wanted for a long time. There have been at least three ideas for how to provide a WebDAV-based user file server. We present the one we chose and its implementation details; two rejected approaches can be found at the end of the document, both for historical interest and to provide replies to those asking why we didn’t do it some other way (including ourselves when, in the fullness of time, we decide to rewrite the fileserver component of the RSP).
2.1 Nublado¶
Abstractly, a lightweight WebDAV server, running as a particular user, with all of that user’s permissions, with the correct filesystems mounted, is the most conceptually simple design we could have.
As it happens, our JupyterLab Controller (AKA
nublado) already provided the user impersonation part of that. What
it does is to spin up a Kubernetes Pod, running as a particular user,
which then runs JupyterLab with a selection of volumes mounted, which
allows the user to work on their own files, and on files shared to them
via POSIX groups.
The new Controller is decoupled rather nicely from JupyterHub: the Hub Spawner interface has been reduced to a series of simple REST calls, and all the impersonation pieces are handled by a combination of Gafaelfawr arbitrating user access and providing delegated tokens as necessary. The controller uses these tokens to bake the resulting userids and groupids into the containers that it spawns.
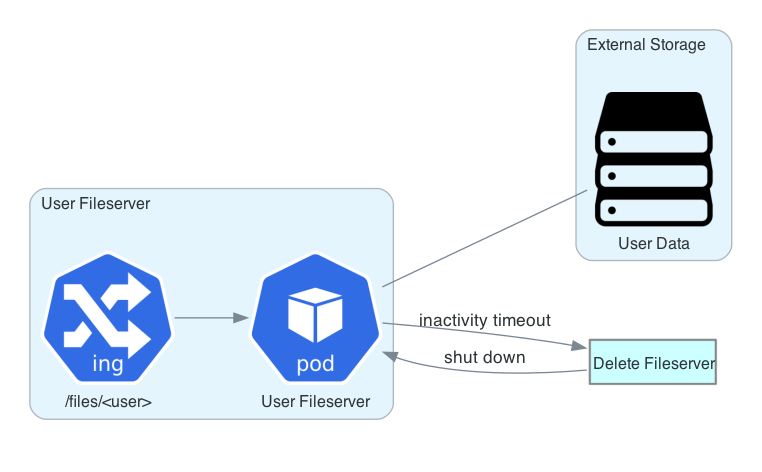
That reduces the problem to writing a simple WebDAV server. We can assume it is already running as the correct user with the correct groups. It must also have an inactivity timeout that shuts down the fileserver after some period with no usage. This must then be plumbed into the JupyterLab Controller, with a route to allow creation of user fileservers, and there must be some mechanism by which shutdown of the fileserver signals the controller to clean up resources.
3 Implementation¶
Containers, at their heart, are just fenced-off processes with their own namespaces for PIDs, file systems, network routing, et cetera. Clearly what we wanted was the minimal container that would support serving files when supplied with a user context.
The Go language turns out to be just about ideal for this. Go does static (or nearly-so) linking. It also has a perfectly serviceable WebDAV server implementation in its standard library. Two minutes of Googling yielded this simple WebDAV-enabled HTTP server which the author was kind enough to allow us to reuse under an MIT license.
The resulting code is known as Worblehat . To the provided
server, we added a few settings to tweak, including an inactivity
timeout and a mechanism for realizing shutdown on timeout. It is
packaged as a single-file container: the only thing in it is the
Worblehat executable, and a mount point (conventionally /mnt) that
serves as the root of the presented tree. Any filesystems mounted into
a user lab are mounted into the fileserver, but with /mnt prepended,
so that the fileserver serves only a single collection.
This presents a minimal attack surface. When the fileserver has
received no file requests (technically, no requests with methods other
than PROPFIND) for the length of its timeout, the process simply
exits.
That was the easy part.
4 Supporting code¶
The much harder part was implementing the machinery in the JupyterLab Controller to automatically create and tear down user fileserver resources on demand.
Much of that effort went into extending the Kubernetes mock API in Safir to support the new objects and methods that the fileserver needs. This cascaded into an effort to replace all the polling loops in the controller with event watches and to streamline the event watch structure.
The controller uses that watch to determine when the fileserver process
has exited (the Pod moves to a terminal state), and triggers cleanup of
all the fileserver objects based on that event. That is effectively
instantaneous when the Pod shuts down. Specifically, the window when
there still exists a valid ingress for the fileserver while the
Worblehat pod is not running is very small. Once the fileserver ingress
is gone, the user WebDAV client may be ill-behaved and keep hammering
the top-level /files ingress (which will catch
/files/<user-without-fileserver) but in practice it is unlikely to
cause issues, since replying with a 405 Method Not Allowed is very
cheap.
The final missing piece was a set of changes to Phalanx to add the new routes and add ClusterRole capabilities for the controller to be able to manipulate the objects that Labs don’t use but Fileservers do.
5 Controller Routes¶
The user fileserver adds three routes to the controller.
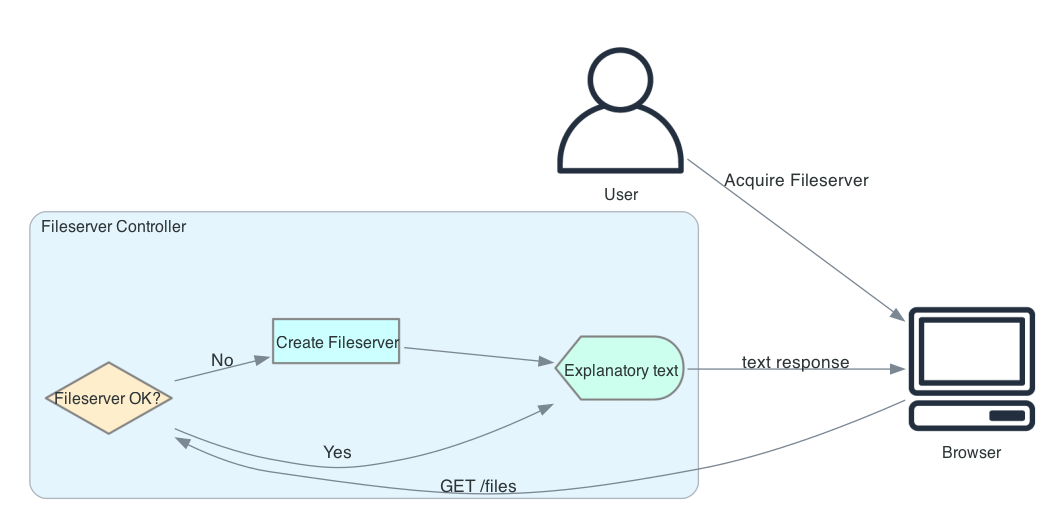
GET /filesCreates fileserver objects for user if necessary and returns usage text. That text instructs a user how to acquire a token for the fileserver and tells the user to direct a WebDAV client with that token to
/files/<username>.Credential scopes required:
exec:notebookGET /nublado/fileserver/v1/usersReturns a list of all users with running fileservers. Example:
[ "adam", "rra" ]
Credential scopes required:
admin:jupyterlabDELETE /nublado/fileserver/v1/<username>Removes fileserver objects (if any) for the specified user.
Credential scopes required:
admin:jupyterlab
6 Fileserver Information Flow¶
6.1 User Requests Fileserver¶
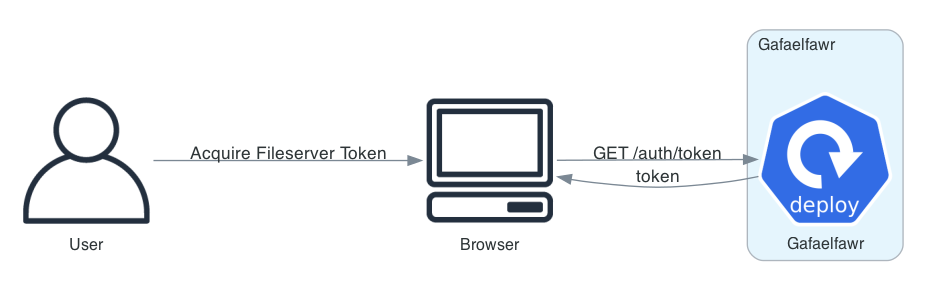
6.2 User Requests Fileserver Token¶
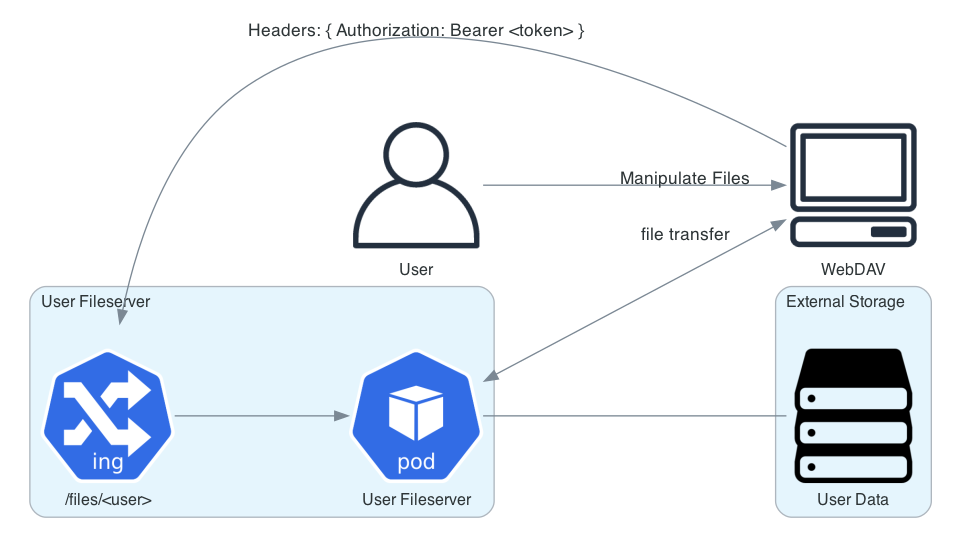
6.3 User Manipulates Files via Fileserver¶
6.4 Fileserver Shuts Down After Timeout¶
7 Other Approaches Considered¶
7.1 Nginx Extensions¶
One approach was started by Brian Van Klaveren several years ago. His idea was to take the built-in rudimentary WebDAV support in Nginx, extend that with https://github.com/arut/nginx-dav-ext-module (which adds the rest of the WebDAV verbs, turning it into a complete WebDAV implementation.) Atop that, Brian would install https://github.com/lsst-dm/legacy-davt which would add user impersonation, allowing the Nginx server to serve files as the requesting user.
This is not prima facie a bad idea. We rely on Nginx for our ingresses in the RSP, and Nginx module creation, while hideous, is thoroughly documented. Granted, to avoid the hideousness, Brian had decided to implement his module in Lua rather than C, which in turn leads to a fairly hard requirement to use the OpenResty Nginx fork (because adding Lua support by hand is extremely tricky). That seemed an odd decision, since most of Brian’s code uses the FFI, and it’s just Lua using C bindings to do system calls to change the various user IDs in effect.
In any event, it didn’t matter. That’s because we need to care about
more than the primary user and group, which are accessible via
setfsuid() and setfsgid() respectively. We also need to care
about the user’s supplementary groups, and we can’t handwave that away
because supplementary group membership is going to be a lot of what
determines whether files in /projects (designated for
collaborations) are accessible.
That’s where this whole project founders. setgroups() exists, but
it is a POSIX interface, and applies process-wide: that is, if any
thread calls setgroups() the resulting change is applied to all
threads in the process. Nginx is a multithreaded web server. What we
really wanted was a process-forking model.
This could have been worked around, perhaps: if we’d gone into the
setgroups() implementation, we might have been able to figure out
which (undocumented) system calls are being used to do the actual
manipulation, steal those, and then just not signal the other
threads within the process; that, probably, would have ended up being a
new kernel module, which is not a maintenance headache we need, and
would necessarily have resulted in injecting ourselves far below the
layer we want to care about. SQuaRE wants to be a consumer of a
Kubernetes service someone else provides; we explicitly don’t care
what’s running in the kernel, as long as we have the capabilities we
require.
Maybe we could have called setfsgid() in a loop for each group in
the user’s groups, retrying the operation until it succeeded or we ran
out of groups, but that would have been a painful performance nightmare.
7.2 Apache¶
Apache was the original force behind WebDAV and the Apache web server has pretty good support for it. Since Apache largely predates threads working very well in the Linux world, it supports a multiprocess model. It might, therefore, have been possible to devise some model that would grab a new process from the process pool and make the appropriate system calls to change the ownership of the process before letting it do work on the user’s behalf.
However, none of us were familiar with Apache modules at anything like the level of detail that would have been required to even know if this was feasible, much less enough to successfully implement an impersonating Apache WebDAV module.